This morning I woke up to a new paper on single image to 3D generation, and I must say I'm honestly mind-blown by how fast this tech is evolving.
My first tests time ago with gaussian splatting were already quite telling, being able to reproduce items in a quite precise way with just a few pics, in contrast with the 100+ pics often needed recommended for photogrammetry. But this exceeds any expectations I had about this new solution. The paper claims to be using a latent difussion model to generate multiple views of the heads and then feeding them to a GS-LRM reconstructor to generate a gaussian splat version of the heads.
The paper claims to be using a latent difussion model to generate multiple views of the heads and then feeding them to a GS-LRM reconstructor to generate a gaussian splat version of the heads.
I am so interested in seeing how they got to train and refine the model. The fact the GS-LRM didn't find big enough discrepancies is amazing.
I am also wondering how actually usable these heads might be without major tweaking, although that does not seem to be a big problem moving forward, as recently I also got to read about Meshtron, a solution which claimed to be able to convert point clouds into actually usable meshes. Removing, therefore, the current need for retopology, baking and other tweaks.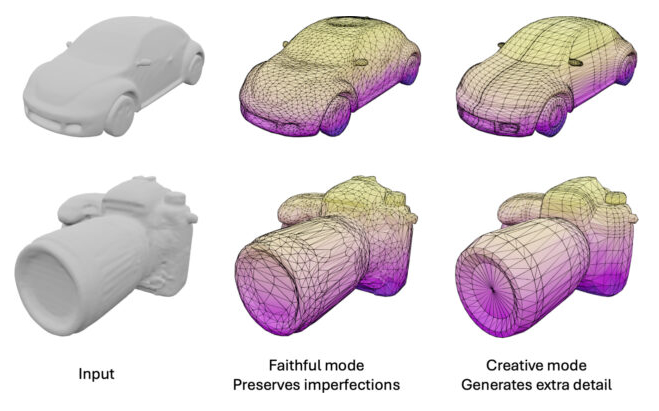
With this in mind I can say I really think we're heading towards this future where 3D asset and character preparation is going to be substantially different from what we know today.
There's still going to be plenty of work for 3D Artists, as I genuinely believe AI can't replace years of experience and actual creativity, but it's going to be far more focused on creating the impossible and tweaking the possible.
I can't wait to hear more about FaceLift or any other advances. Like the two minutes paper Youtube guy says: what a time to be alive!
Built from Takuya Matsuyama's template.
© 2026 Danel Sánchez. All Rights Reserved.